Lexer
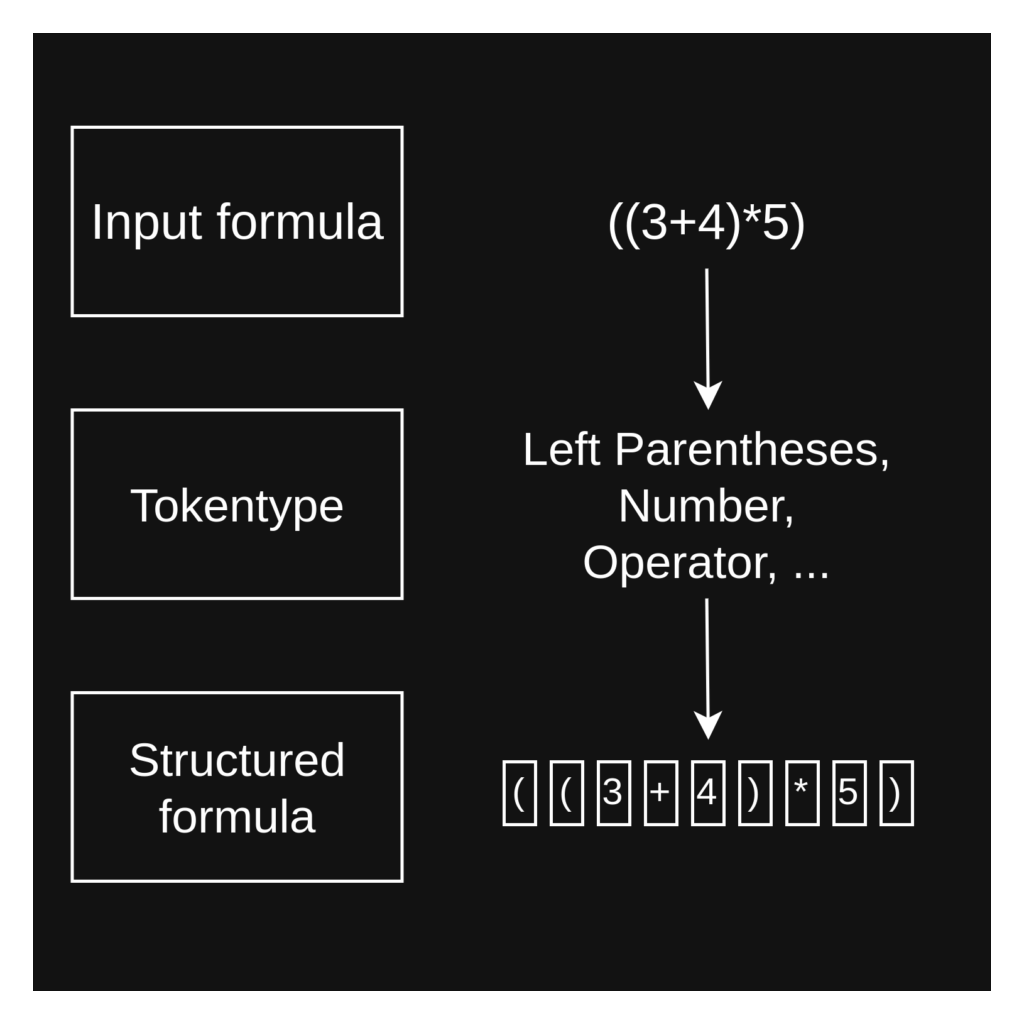
The Lexer is the initial stage for processing an input expression. It takes a raw string, such as a mathematical formula, and scans it character by character. Its main task is to break down this input into a sequence of meaningful units called ‘Tokens’.
While scanning, it groups characters and assigns each group a specific TokenType, distinguishing between numbers, operators, and identifiers. Furthermore, the Lexer is designed to recognize specific keywords, including important mathematical functions like ‘log’, ‘sin’, and ‘cos’.
Each generated Token, which holds both its original text and its classified type, is then passed on to the Parser. The Parser relies on this structured sequence of Tokens to understand the grammatical structure of the original expression and process it further.
Parser
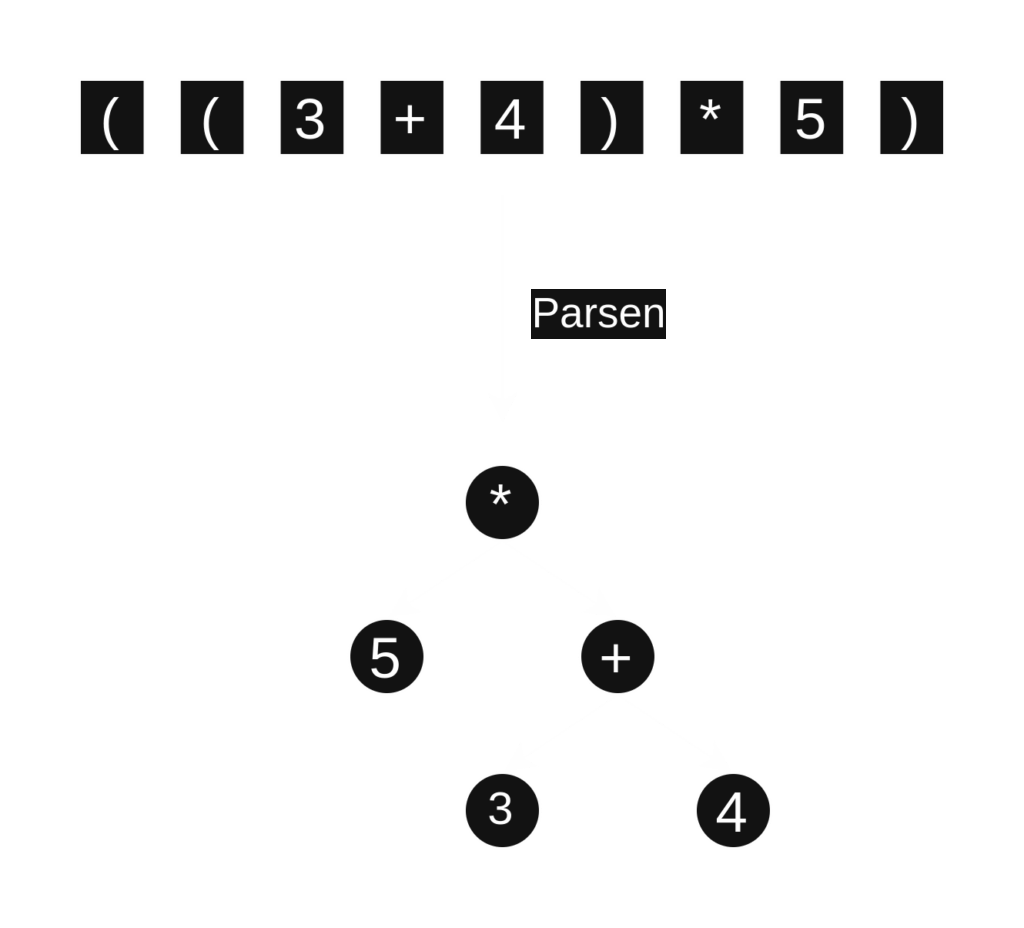
The Parser takes the stream of Tokens generated by the Lexer and determines the grammatical structure of the original expression. It acts as the “Syntax Checker” and “Structure Builder”, ensuring the sequence of tokens follows the defined rules of the language, much like checking a sentence for proper grammar.
Using the Tokens, the Parser figures out how numbers, operators, and functions relate to each other. It understands operator precedence, knowing, for example, that multiplication should typically happen before addition. It recognizes parenthesized expressions, unary operations (like negation), and various function calls such as log, sin, min, or max.
As it processes the tokens, the Parser constructs an internal representation, often an “expression tree”. This tree mirrors the hierarchical structure of the original formula, making it clear how different parts of the expression depend on each other. This structured representation is the final output of the parsing stage, ready to be evaluated or used by other parts of the system.